

LLM Evaluation: Ansätze, Metriken und Best Practices
Die Bewertung von Large Language Models (LLMs) ist der Prozess der Messung und Beurteilung, wie gut ein Sprachmodell anhand definierter Kriterien und Aufgaben funktioniert. In der Praxis bedeutet dies, die Ausgaben eines LLMs auf Qualität (Genauigkeit, Kohärenz, etc.), Sicherheit und Übereinstimmung mit dem vorgesehenen Einsatzzweck zu testen. Eine gründliche Evaluation ist nicht nur ein technischer Haken, sie ist entscheidend, um sicherzustellen, dass diese KI-Modelle zuverlässig, präzise und für geschäftliche Zwecke geeignet sind. Ohne eine ordnungsgemäße Bewertung können LLMs voreingenommene, fehlerhafte oder sogar schädliche Inhalte erzeugen.
Die LLM-Bewertung bildet die Grundlage für Vertrauen und Effektivität in KI-Lösungen. Zum Beispiel führt das Finanzunternehmen Morgan Stanley den Erfolg seiner KI für Kundenberater auf ein „robustes Evaluierungsframework“ zurück, das sicherstellt, dass das Modell konstant die hohen Standards erfüllt, die Nutzer erwarten. Anders gesagt: Systematisches Testen gab dem Management das Vertrauen, dass die Antworten der KI in der Praxis verlässlich sind. Da generative KI inzwischen von 65% der Unternehmen weltweit eingesetzt wird, ist ein strukturiertes Bewertungsverfahren zu einer geschäftlichen Notwendigkeit geworden. Es ist der Mechanismus, der es Unternehmen ermöglicht, die Vorteile von KI zu nutzen und gleichzeitig Risiken zu kontrollieren. Wie Gartner betont, sollten Unternehmen LLMs basierend auf dem geschäftlichen Nutzen bewerten – also darauf, ob das Modell skalierbar bleibt, effizient arbeitet und langfristigen Wert liefert, anstatt dem neuesten KI-Hype hinterherzulaufen.
Wie man LLM-Modelle bewertet: Ansätze und Strategien
1. Labortests vs. Bewertung in realen Szenarien
Bei der Bewertung von LLMs kombinieren Unternehmen in der Regel Labortests mit Bewertungen unter realen Bedingungen, um ein vollständiges Bild zu erhalten. Eine Laborevaluation ist wie ein kontrolliertes Experiment, bei dem ein LLM anhand isolierter Metriken mit vorbereiteten Datensätzen oder Prompts getestet wird. In diesem Szenario könnte man dem Modell 1.000 verschiedene Fragen stellen und die Genauigkeit messen oder seine Ausgabe mit einer bekannten Referenz vergleichen. Dies ist nützlich für kontrollierte Vergleiche, z. B. um zu prüfen, wie oft das Modell die richtige Antwort bei einem Satz von Q&A-Paaren liefert oder um die Perplexity (ein Maß dafür, wie gut das Modell Text vorhersagt) auf einem Validierungskorpus zu messen. Solche Modellevaluierungen betrachten das LLM isoliert und bewerten dessen Kernfähigkeiten auf wiederholbare Weise. Das ergibt quantitative Benchmarks und hilft bei der Feinabstimmung des Modells, bevor Nutzer es zu sehen bekommen. Labortests allein reichen jedoch nicht aus.
Der nächste Schritt ist der Einsatz des Modells in einem realistischen Nutzungsszenario: die Systembewertung. Die Bewertung in der Praxis setzt das Modell der Unvorhersehbarkeit realer Nutzung aus. Die Systembewertung betrachtet die Leistung des LLMs, wenn es in eine Anwendung oder einen Workflow integriert ist, reale Nutzereingaben verarbeitet und mit anderen Komponenten interagiert. Dies kann z. B. eine Pilotimplementierung sein, ein A/B-Test mit einer Teilmenge von Nutzern oder der Einsatz des Modells in einer simulierten Geschäftssituation.
Beide Ansätze sind wichtig: Labortests sichern eine Grundqualität unter bekannten Bedingungen, während Live-Tests Probleme aufdecken, die nur in der Praxis auftreten (z. B. ungewöhnliches Verhalten in Grenzfällen oder Performance-Engpässe). Im Fall von Morgan Stanley testete das Team GPT-4 mit realen Anwendungsfällen und internen Expert:innen, bevor es vollständig eingeführt wurde. Sie führten domänenspezifische Bewertungstests durch, z. B. das Zusammenfassen von Finanzdokumenten, und ließen menschliche Berater die Antworten der KI auf Genauigkeit und Kohärenz bewerten. Diese Kombination aus Offline-Metriken und human-in-the-loop-Tests ermöglichte eine gezielte Optimierung der Prompts und eine höhere Qualität der Ausgaben.
2. Einzelnes Modell vs. LLM-gestützte Anwendung
Ein weiterer strategischer Aspekt ist die Frage, ob man ein einzelnes Modell oder eine LLM-basierte Anwendung bewertet. Das Testen eines Rohmodells (z. B. über eine API) unterscheidet sich vom Testen innerhalb einer App oder eines Produkts. Beim Testen eines einzelnen Modells könnte es darum gehen: Gibt das Modell auf einen Prompt die erwartete Antwort? Vieles davon lässt sich mit vordefinierten Abfragen und bekannten Ergebnissen automatisieren. Doch wenn das Modell Teil einer Anwendung ist (z. B. ein Chatbot oder ein Dokumentensuchtool), muss das gesamte System bewertet werden: Kann die Benutzeroberfläche die Nutzerabsicht korrekt erfassen und an das LLM übergeben? Wird die Antwort des LLM korrekt in die App integriert? Und ist die gesamte Nutzererfahrung effektiv (angemessene Antwortzeit, verständliche Ausgabe, etc.)?
Systembewertungen bringen oft zusätzliche Metriken ins Spiel, z. B. zur Nutzererfahrung (wie Zufriedenheitswerte oder Zeit bis zur nützlichen Antwort) sowie Robustheitstests (z. B. bei verrauschten oder adversarialen Eingaben). Durch die Kombination von modellzentrierter und systemweiter Bewertung stellen Unternehmen sicher, dass sie nicht nur ein technisch starkes Modell wählen, sondern eine praktikable und benutzerfreundliche KI-Lösung für den produktiven Einsatz aufbauen.
3. Automatisierte Bewertung vs. menschliche Beurteilung
Auch dieser Punkt ist zentral für die Evaluierungsstrategie. Bei der automatisierten Bewertung werden Algorithmen und Metriken eingesetzt, um die Ausgaben des Modells zu beurteilen. Zum Beispiel kann man automatisierte Metriken nutzen, um die Antwort des Modells mit einer Referenzantwort zu vergleichen oder Skripte laufen lassen, die prüfen, ob bestimmte verbotene Wörter vorkommen. Solche Tests sind schnell, skalierbar und konsistent – ideal etwa für Regressionstests (ob eine neue Modellversion bei bestimmten Aufgaben besser oder schlechter geworden ist).
Doch automatisierte Metriken erfassen oft nicht das ganze Bild. Sie übersehen Nuancen wie z. B., ob eine Antwort gut erklärt oder der Tonfall angemessen ist. Deshalb bleibt die menschliche Bewertung unverzichtbar, wenn es um feine Einschätzungen geht. Menschen können beurteilen, ob eine Antwort hilfreich ist, ob eine Erzählung kohärent ist oder ob Konversationsnormen eingehalten werden. Zum Beispiel können Menschen feststellen, ob eine Erklärung logisch und überzeugend ist – etwas, das eine automatisierte Metrik nicht zuverlässig misst.
In der Praxis ist ein gemischter Ansatz oft am besten: Automatisierte Tests übernehmen das Grobe (z. B. Tausende Prompts durch das Modell laufen lassen, Fehler oder zu lange/kurze Antworten identifizieren), dann konzentrieren sich menschliche Bewerter auf die Feinbewertung einer Auswahl. Viele Unternehmen erstellen Bewertungssets und lassen menschliche Reviewer die Modellantworten in Kategorien wie Korrektheit, Klarheit und Angemessenheit bewerten. Diese menschlichen Bewertungen dienen dann als „Goldstandard“, um Modelle zu vergleichen oder Prompts zu optimieren.
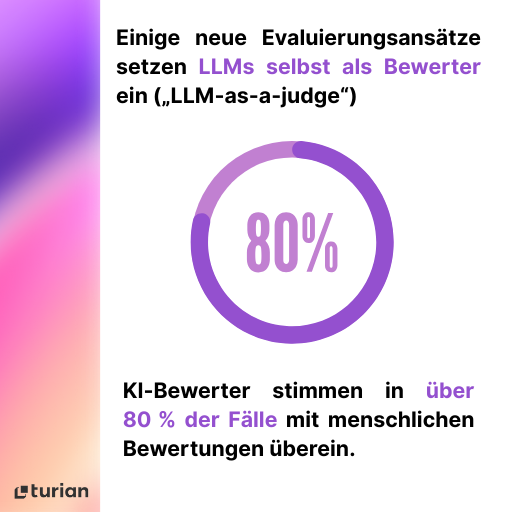
Interessanterweise setzen einige neue Ansätze selbst LLMs als Bewerter ein („LLM-as-a-judge“). Dabei beurteilt ein KI-Modell die Ausgaben eines anderen Modells. Studien zeigen, dass solche KI-Bewerter mit menschlichen Bewertungen zu über 80 % übereinstimmen – eine vielversprechende skalierbare Ergänzung menschlicher Bewertung. Auch wenn sie nicht perfekt sind, werden LLM-basierte Bewerter zunehmend zur Ergänzung eingesetzt.
Die Bewertung eines LLM ist ein vielschichtiger Prozess: Beginnen Sie im Labor mit kontrollierten Tests des Modells selbst, und gehen Sie dann über zu Szenarien aus der Praxis, um zu sehen, wie es sich im Kontext verhält. Nutzen Sie automatisierte Metriken für objektive, wiederholbare Messungen, und ergänzen Sie diese durch menschliche Beurteilungen, um Qualität und Nuancen zu erfassen. Und vor allem: Bewerten Sie nicht nur die reine Ausgabe des Modells, sondern die Leistung der gesamten KI-gestützten Lösung in Bezug auf den Nutzen für Endnutzer.
{{cta="/de/cta/automate-quality-management-with-ai-agents"}}
Bewertung der LLM-Leistung: Wichtige Metriken und Benchmarks
Um die Leistung von LLMs systematisch zu bewerten, greifen Unternehmen auf eine Reihe zentraler Metriken zurück, die verschiedene Dimensionen der Ausgabequalität erfassen. Zu den wichtigsten Metriken und Bewertungskriterien gehören:
1. Genauigkeit und faktische Korrektheit
Im Kern geht es darum, ob die Ausgabe des LLM korrekt ist. Genauigkeit kann bedeuten, dass die Antwort sachlich richtig ist oder dass sie die Nutzeranfrage korrekt erfüllt. Bei einer Mathematikaufgabe oder Ja-/Nein-Frage: Hat das Modell die richtige Antwort gegeben? Bei generativen Aufgaben bedeutet faktische Korrektheit oft, sogenannte „Halluzinationen“ zu vermeiden – also sicherzustellen, dass die Aussagen des Modells auf der Wahrheit oder auf bereitgestellten Daten basieren. Gartner spricht hierbei von Genauigkeit und Fundierung, also: Die Antwort sollte faktenbasiert und präzise sein. Genauigkeit wird z. B. über „Exact Match Scores“ bei Q&A oder über den Abgleich mit bekannten Fakten gemessen. Wenn ein LLM Informationen aus einer firmeninternen Wissensdatenbank abruft, könnte es danach bewertet werden, wie viele seiner Antworten ausschließlich korrekte und verifizierbare Informationen enthalten.
2. Kohärenz und Sprachfluss
Kohärenz misst, wie logisch konsistent und gut strukturiert die Ausgabe ist, während Sprachfluss die grammatikalische und sprachliche Qualität beschreibt. Ein LLM kann inhaltlich korrekt sein, aber eine unverständliche oder schlecht strukturierte Erklärung liefern. Bewertet wird, ob die Antwort logisch aufgebaut ist, beim Thema bleibt und einfach zu verstehen ist. Diese Merkmale werden meist von Menschen beurteilt, es gibt aber auch Näherungswerte wie Perplexity (niedrigere Perplexity korreliert oft mit flüssigerem Text) oder Metriken, die den Output mit menschlich geschriebenen Texten vergleichen.
3. Relevanz
Relevanz bewertet, wie gut die Ausgabe des Modells zur Eingabe bzw. zur Nutzerfrage passt. Eine Antwort kann inhaltlich korrekt sein, aber nutzlos, wenn sie nicht zur gestellten Frage oder zum Kontext passt. LLM-Evaluierungen prüfen deshalb, ob die Antwort thematisch passt. Das kann durch menschliche Bewertungen („Wie relevant ist diese Antwort zur Frage?“) oder automatisiert (z. B. durch Abgleich der Schlüsselbegriffe) erfolgen. Gartner nennt Relevanz und „Recall“ als Schlüsselkriterien: Die Ausgabe sollte den geschäftlichen Anforderungen entsprechen und alle wichtigen Informationen abdecken.
4. Compliance und Sicherheit
Dies sind besonders wichtige qualitative Metriken, insbesondere für Unternehmen oder öffentliche Anwendungen. Compliance bedeutet, dass der Output geltendem Recht, Vorschriften und internen Richtlinien entspricht. Sicherheit stellt sicher, dass das Modell keine schädlichen oder anstößigen Inhalte erzeugt. Dazu gehört z. B. das Fehlen von Hassrede, Belästigung oder diskriminierender Sprache sowie das Vermeiden gefährlicher Anweisungen (etwa keine Empfehlungen, die Schaden verursachen könnten). Viele Unternehmen messen dies inzwischen gezielt – etwa über Tests auf gesperrte Begriffe oder Bias-Checks. Ein LLM kann z. B. anhand eines „Toxicity Scores“ (Grad an problematischen Inhalten) bewertet werden oder durch Eingaben zu verschiedenen demografischen Gruppen, um die Fairness zu überprüfen. Gartner zählt Sicherheit und Bias-Erkennung zu expliziten Bewertungskriterien – problematische Ausgaben sollen erkannt und entsprechende Risiken reduziert werden.
{{cta="/de/cta/validate-certificates-instantly-with-ai-agents"}}
5. Effizienz und Performance
Neben dem Inhalt prüfen Unternehmen auch die Effizienz des Modells. Dazu gehören Geschwindigkeit (Latenz): Wie schnell wird eine Antwort generiert?; sowie Skalierbarkeit: Kann das Modell viele Anfragen oder große Dokumente verarbeiten, ohne auszufallen oder teuer zu werden? Auch der Rechenaufwand pro Anfrage zählt: Wie viele Ressourcen werden pro Anfrage verbraucht? Diese Faktoren wirken sich direkt auf Benutzererfahrung und Wirtschaftlichkeit aus. Ein KI-Assistent, der 30 Sekunden für eine Antwort braucht, wird kaum genutzt. Oder: Wenn jede Abfrage sehr hohe Cloud-Kosten verursacht, ist das Modell nicht skalierbar. Daher überwachen Teams Werte wie durchschnittliche Antwortzeit, Durchsatz (Anfragen pro Sekunde) oder Kosten pro Anfrage. Gartner betont, dass „Skalierbarkeit, Effizienz und langfristiger Nutzen“ zentrale Kriterien für die geschäftliche Eignung eines LLMs sind. In der Praxis setzen Teams häufig Zielwerte wie: 95 % der Antworten sollen in unter 2 Sekunden erfolgen oder das System soll 100 parallele Nutzer ohne Leistungseinbruch unterstützen.
6. Nutzerzufriedenheit und UX-Metriken
Dies ist eine qualitative Ergebnis-Metrik: Sind die Nutzer mit den Antworten und der Erfahrung zufrieden? Das kann per Umfrage („Bewerten Sie diese Antwort von 1–5“), Feedback-Schaltflächen (Daumen hoch/runter) oder durch Analyse des Nutzungsverhaltens (brechen Nutzer den Chat ab oder machen sie weiter?) gemessen werden. Ein Modell kann objektiv gute Ergebnisse liefern, aber dennoch nicht die Nutzerbedürfnisse erfüllen – z. B. wegen unpassendem Tonfall oder unklarer Formatierung. Nutzerfeedback im Live-Betrieb ist daher entscheidend. Manche Unternehmen nutzen NPS (Net Promoter Score) oder CSAT (Customer Satisfaction Score) speziell für ihre KI-Funktionen, andere achten auf Wiederverwendung und Interaktionsraten. Hohe Nutzerzufriedenheit korreliert oft mit Kohärenz und Relevanz, bleibt aber ein eigenständiger Bewertungsfaktor.
7. Kontextverständnis
Damit ist die Fähigkeit des Modells gemeint, Nuancen zu verstehen, Kontext in einem Dialog zu behalten und „Alltagslogik“ zu zeigen. Es ist schwer zu quantifizieren, aber essenziell für komplexe Aufgaben. In mehrstufigen Dialogen: Merkt sich das Modell frühere Aussagen und reagiert entsprechend? Versteht es implizite Bedeutungen oder subtile Anfragen? Bewertet wird dies oft über szenariobasierte Prompts oder Rollenspiel-Dialoge. Ein weiterer Aspekt: Kann das Modell domänenspezifischen Kontext nutzen – z. B. juristische oder medizinische Fachsprache korrekt anwenden und bei den Fakten bleiben? Unternehmen entwickeln dafür oft eigene Testsets mit realistischen Szenarien, etwa ein simuliertes Kundenservice-Gespräch, um zu sehen, ob die KI natürlich folgen kann. Dies wird häufig qualitativ durch Expert:innen bewertet: Sie analysieren Transkripte und bewerten, wie gut das Modell den Kontext beibehält und passende Lösungen liefert.
Um diese verschiedenen Aspekte zu messen, hat die KI-Community anerkannte Benchmarks entwickelt, die als Leistungsmaßstab dienen. Weit verbreitete Benchmarks sind:

GLUE (General Language Understanding Evaluation)
Ein Testpaket zur Bewertung des Sprachverständnisses, das Aufgaben wie Sentimentanalyse, Fragebeantwortung und Textverständnis abdeckt. GLUE bietet eine umfassende Messung dafür, wie gut ein Modell Bedeutung und Kontext über verschiedene Aufgaben hinweg erfasst. Ein hoher GLUE-Score zeigt, dass das Modell verschiedene NLP-Aufgaben auf einem mit der menschlichen Leistung vergleichbaren Niveau bewältigen kann. Unternehmen und Forschungseinrichtungen nutzen GLUE, um Modelle auf standardisierte Weise zu vergleichen – es fungiert gewissermaßen als gemeinsame Bewertungsgrundlage für Sprachmodellfähigkeiten.
SuperGLUE
Eine aktualisierte, anspruchsvollere Version von GLUE mit schwierigeren Sprachaufgaben (z. B. Ursache-Wirkung-Verständnis, nuanciertes logisches Denken). Führende Modelle werden häufig mit SuperGLUE bewertet, um fortgeschrittenes Sprachverständnis nachzuweisen. Dieser Benchmark ist besonders relevant, wenn man ein LLM auswählt oder feinjustiert: Ein Modell mit guter SuperGLUE-Leistung gilt als besonders „verständnisstark“.
MMLU (Massive Multi-Task Language Understanding)
Ein Benchmark, der das Wissen und das logische Denkvermögen eines LLM über 57 Fachgebiete hinweg testet – von Geschichte und Literatur bis Mathematik und Biologie. MMLU ist im Grunde eine akademische Prüfung für Modelle. Dieser Benchmark ist hilfreich, um die Breite und Tiefe des Wissens zu bewerten: Wenn man ein Modell als breit aufgestellten Wissensassistenten einsetzen will, sollte es auf MMLU gut abschneiden, um sicherzustellen, dass es viele Themenfelder abdecken kann. Hohe Werte auf MMLU deuten darauf hin, dass das Modell Fakten abrufen und Probleme in vielen Bereichen lösen kann – ein Indikator für Allgemeinwissen und Denkfähigkeit.
HELM (Holistic Evaluation of Language Models)
Ein umfassender Bewertungsrahmen der Stanford University, der Sprachmodelle anhand einer Vielzahl von Metriken und Szenarien beurteilt – für einen ganzheitlichen Blick auf die Leistung. HELM deckt 7 Hauptmetriken ab (Genauigkeit, Robustheit, Kalibrierung, Fairness, Bias, toxische Inhalte, Effizienz) sowie 26 verschiedene Szenarien. So erhalten Unternehmen ein mehrdimensionales Leistungsprofil eines LLM. HELM kann z. B. das Verhalten eines Modells bei potenziellen Fehlinformationen oder Vorurteilen testen. Ein Unternehmen kann HELM-Ergebnisse nutzen, um zu erkennen, ob ein Modell zwar hohe Genauigkeit liefert, aber bei Fairness Defizite aufweist – und daraus ableiten, wo zusätzliche Schutzmaßnahmen oder Trainings nötig sind.
Branchenspezifische Benchmarks
Neben allgemeinen Benchmarks gibt es auch Tests, die auf bestimmte Branchen oder Aufgaben zugeschnitten sind. Im medizinischen Bereich gibt es z. B. PubMedQA für biomedizinische Fragebeantwortung oder medizinische Teilbereiche von MMLU. Der juristische Bereich kann Benchmarks wie Prüfungsfragen für das Bar Exam oder Zusammenfassungen aus CaseLAW nutzen, um zu prüfen, ob ein Modell juristische Texte korrekt versteht. Wer ein LLM in einem spezialisierten Bereich einsetzt, sollte es mit den jeweiligen branchenspezifischen Benchmarks testen, um sicherzustellen, dass es den Anforderungen an Genauigkeit und Verlässlichkeit genügt.
Der Einsatz etablierter Benchmarks bietet eine wichtige Referenz: Man kann das gewählte oder feinjustierte Modell mit bekannten Werten vergleichen (z. B. „Unser Modell erreicht beim Summarizing eine ROUGE-Bewertung nahe dem aktuellen Stand der Technik“ oder „Modell X übertrifft Modell Y im MMLU um 5 Punkte und zeigt damit mehr Allgemeinwissen“). Genauso wichtig ist es aber, Benchmarks durch eigene Tests zu ergänzen, die auf die konkreten Anwendungsfälle abgestimmt sind. Benchmarks zeigen die generellen Fähigkeiten eines Modells, aber nur unternehmensspezifische Metriken (z. B. „Erfolgsquote bei der Beantwortung der 100 häufigsten Kundenfragen“) sagen aus, ob das Modell im Geschäftsbetrieb tatsächlich liefert. In der Praxis kombinieren Unternehmen beides: Sie nutzen Benchmarks als grobe Orientierung, um Modelle vorzuselektieren, und führen dann detaillierte interne Tests durch, um die endgültige Entscheidung zu treffen.
Best Practices für eine effektive LLM-Evaluierung
Basierend auf diesen Erkenntnissen und branchenspezifischen Empfehlungen haben sich mehrere Best Practices herausgebildet, um die Evaluierung von LLMs effektiv durchzuführen:
1. Klare Ziele und Erfolgskriterien von Anfang an definieren
Bevor Sie mit der Evaluierung beginnen, sollten Sie klar festlegen, was „gute Leistung“ für Ihre Anwendung bedeutet. Verknüpfen Sie die Evaluierungskriterien des LLM mit geschäftlichen Zielsetzungen. Wenn das Ziel z. B. darin besteht, die Bearbeitungszeit im Kundenservice zu verkürzen, sollte Ihre Evaluierung die Korrektheit der Antworten auf häufig gestellte Fragen sowie die Fähigkeit des Modells bewerten, zu erkennen, wann ein Mensch übernehmen sollte. Klare, anwendungsbezogene Metriken lenken den Fokus auf das, was wirklich zählt.
2. Kombination aus Benchmark- und benutzerdefinierten Tests verwenden
Nutzen Sie bekannte Benchmarks, um sich ein Bild von den Modellfähigkeiten zu machen – aber gehen Sie darüber hinaus. Passen Sie die Evaluierung an Ihre Branche und Ihre Daten an. Wenn Sie z. B. in einer Kanzlei arbeiten, sollten juristische Fallzusammenfassungen Teil der Tests sein; wenn Sie einen Coding-Assistenten entwickeln, dann integrieren Sie Aufgaben zum Programmieren und Debugging. Best Practice ist es, ein realistisches Testset zu erstellen, das typische Aufgaben und Grenzfälle Ihres Einsatzszenarios abbildet.
3. Die richtigen Personen einbeziehen (Human-in-the-Loop)
Evaluierung ist keine reine Aufgabe für Data Scientists. Eine interdisziplinäre Beteiligung ist Best Practice. Fachexpertinnen und -experten können Relevanz und Korrektheit im Kontext bewerten (z. B. ein Arzt bei medizinischen Antworten), Compliance-Teams identifizieren regulatorisch problematische Inhalte, und Endnutzer oder UX-Expertinnen beurteilen Tonalität und Verständlichkeit. Menschen „im Loop“ sind besonders wichtig bei subjektiven Kriterien wie Nützlichkeit, Empathie oder Werten des Unternehmens. Zudem sollten Rollen und Verantwortlichkeiten im Evaluierungsprozess klar definiert sein – zum Beispiel: Wer entscheidet letztlich, ob das Modell live gehen darf? Deloitte empfiehlt, die Rollen aller Beteiligten entlang des KI-Lebenszyklus festzulegen.
4. Ein rigoroses Testprotokoll etablieren
Testen Sie das Modell nicht nur mit idealen Eingaben. Prüfen Sie gezielt seine Schwächen und Grenzen. Diese Art von Tests wird auch „Red Teaming“ genannt. Best Practices beinhalten Tests mit schwierigen oder provozierenden Eingaben: doppeldeutige Fragen, falsche Annahmen oder Versuche, das Modell zu verbotenen Aussagen zu verleiten. Auf diese Weise lassen sich Schwachstellen erkennen, die unter realen oder böswilligen Bedingungen auftreten könnten.
5. Kontinuierliches Monitoring und Evaluierung im Live-Betrieb (iterative Evaluierung)
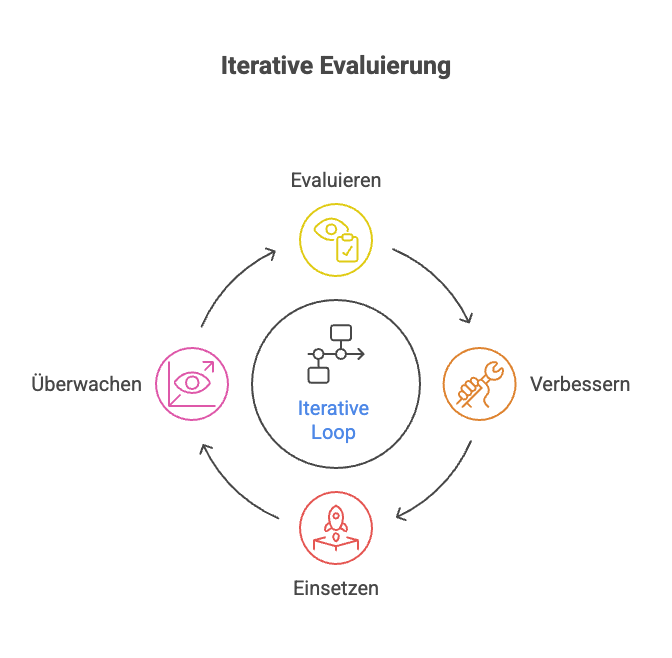
Die Evaluierung von LLMs ist keine einmalige Aufgabe. Nach der Einführung ändern sich reale Bedingungen ständig: Nutzerverhalten entwickelt sich, neue Anwendungsfälle entstehen, oder die Modellleistung driftet mit der Zeit. Etablieren Sie ein fortlaufendes Monitoring, das wichtige Metriken im Betrieb beobachtet. Beispiel: Wöchentliche Erhebung der Rate strittiger Antworten oder von Nutzerunzufriedenheitssignalen. Viele Unternehmen implementieren automatisiertes Monitoring – etwa durch Protokollierung von Ausgaben, Scans auf Regelverletzungen oder regelmäßige Re-Tests mit einem festgelegten Datensatz. Ein iterativer Zyklus aus Evaluieren → Verbessern → Einführen → Überwachen → Evaluieren… stellt sicher, dass die Modellqualität erhalten bleibt oder sich verbessert, statt zu verschlechtern. So lassen sich auch neue Erfolgskriterien bei Bedarf integrieren.
6. Regelmäßiges Benchmarking und Nachkalibrierung
Es ist sinnvoll, die Leistung des Modells regelmäßig zu messen und mit Alternativen zu vergleichen. Das kann bedeuten, dass vierteljährlich derselbe Standardtest durchgeführt wird, um Rückschritte zu erkennen, oder dass das eigene Modell mit einem neuen Modell auf dem Markt verglichen wird. Solches Benchmarking fungiert als Frühwarnsystem für Modell-Drift oder neue Schwächen. Es hilft zudem, den Effekt von Modell-Updates oder Fine-Tuning zu quantifizieren: Neue Versionen sollten anhand der gleichen Metriken bewertet werden, um zu sehen, ob sie tatsächlich besser sind (und keine neuen Probleme verursachen).
7. Dokumentation und Governance des Evaluierungsprozesses
Behandeln Sie Evaluierung als festen Bestandteil Ihrer AI-Governance. Halten Sie Ergebnisse, Entscheidungen und akzeptierte Kompromisse fest. Diese Dokumentation ist wertvoll für die Compliance (z. B. als Nachweis der sorgfältigen Validierung) und für internes Lernen. Best Practice ist ein Evaluierungsbericht für jedes wichtige Modell-Rollout, der zusammenfasst: Was wurde getestet, von wem, mit welchen Ergebnissen und Empfehlungen. Die Unternehmensleitung sollte als Teil der Governance diese Ergebnisse prüfen – wie bei einer Qualitätsfreigabe.
8. Evaluierungskriterien regelmäßig aktualisieren
Mit der Zeit erkennen Sie vielleicht, dass neue Metriken gebraucht werden. Vielleicht ergibt sich aus Nutzerfeedback, dass Konsistenz ein Problem ist (d. h. gleiche Fragen liefern unterschiedliche Antworten) – dann könnte ein „Konsistenz-Check“ sinnvoll sein. Oder Ihr Produkt wird international, also müssen Sie nun auch fremdsprachige Leistungen testen. Best Practice ist es, regelmäßig zu überprüfen, ob Ihre Evaluierungsstrategie noch alle relevanten Aspekte abdeckt. Auch die LLM-Landschaft entwickelt sich – neue Benchmarks und Evaluierungsmethoden (z. B. zur Bewertung von Argumentationsfähigkeit oder Wahrheitsgehalt) entstehen laufend. Wer sich hier informiert hält und neue Methoden integriert, verbessert seinen Evaluierungsrahmen stetig.
Durch Anwendung dieser Best Practices erhöhen Unternehmen ihre Chancen deutlich, LLMs erfolgreich einzusetzen. Ein robuster Evaluierungsprozess erkennt Probleme frühzeitig und sorgt dafür, dass das Team besser versteht, wie das Modell arbeitet – ein entscheidender Vorteil für Wartung und Weiterentwicklung.
Fazit: So gelingt die LLM-Evaluierung für Ihr Unternehmen
Wie gezeigt, ist die Evaluierung von Large Language Models ein vielschichtiger Prozess – doch sie zahlt sich aus: in Form von höherer Genauigkeit, Zuverlässigkeit und erfolgreicher Nutzung im Unternehmen.
Eine gründliche Evaluierung ist die Grundlage für eine vertrauenswürdige und wirksame Einführung von KI. Sie macht aus der Arbeit mit fortgeschrittener KI keine Kunst, sondern eine mess- und steuerbare Disziplin. Unternehmen, die in strukturierte Evaluierungsprozesse investieren, erreichen ihre Ziele häufiger, bieten bessere Nutzererlebnisse und vermeiden unerwünschte Nebenwirkungen.
Gerade in einer Zeit rasanter technologischer Entwicklung ist es die systematische Evaluierung, die verantwortungsvolles Wachstum ermöglicht. Sie schafft die Voraussetzungen dafür, dass Unternehmen generative KI mit Zuversicht einsetzen – in dem Wissen, dass Leistung und Risiken unter Kontrolle sind.
Mit einem kontinuierlichen, umfassenden und geschäftsorientierten Evaluierungsprozess können Unternehmen das volle Potenzial von LLMs ausschöpfen, Qualität und Vertrauen sichern und sich einen Wettbewerbsvorteil in der KI-gestützten Zukunft verschaffen.



